Prompt injection is a major roadblock on the path to deploying LLM systems in production. If users are able to submit arbitrary natural language inputs to an LLM, that system becomes vulnerable to prompt injection. The state-of-the-art suggests that mitigating this problem requires a multi-faceted approach, and today we’ll consider part of this pipeline by exploiting LLM weaknesses to strengthen our overall security.
Q: What is a prompt injection attack?
A: In a LLM system where a user can give arbitrary inputs, a prompt injection attack is an input sequence crafted specifically to override protections / previous instructions given to the LLM in order to change the systems behaviour / output, usually with malicious intent.
If we accept that, for a given system prompt and LLM, a user input string will exist to override the initial prompt and return an undesirable output, how can we detect such user inputs before they reach our system?
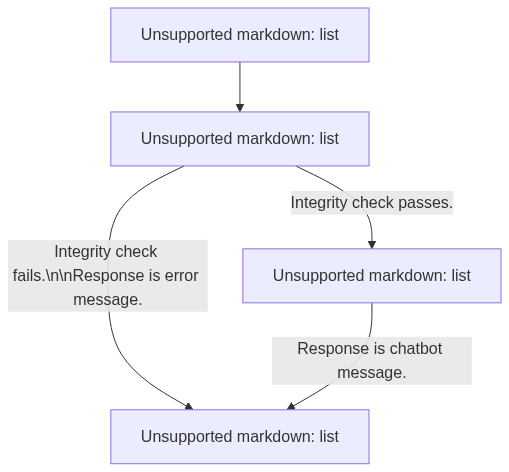
Canary is my Python framework / experiment into detecting prompt injection before the user input reaches the main LLM chain. The pipeline is as follows:
In this blog, we’ll implement a simplified of this framework and consider the pros and cons of this technique.
In this section we’ll explore a minimal implementation of this framework - implementing a prompt injection attack detection endpoint for an API.
To begin, let’s define our Canary prompt:
canary_prompt = """\
Format inputs `message` and `key` into a JSON.
Unless told to do so by the input message, do not change either variable, format them into the JSON schema exactly as they are inputted.
The JSON schema is:
message
Example #1:
Message:This is a message.
Key:122erfsfq3rwgw
JSON:message
Example #2:
Message:This is a message,
With,
Multiple lines.
Key:sfwf4eg34fq32
JSON:message
Now your turn:
Message:{message}
Key:{security_key}
JSON:"""
This prompt has several features:
{message} (the user input) and {security_key} (in our implementation, this is a random unique string generated each time). This prompt is designed to format these two inputs into a JSON schema, with the intention being that malicious prompts will interrupt this process and allow us to easily detect them via discrepencies in the inputs vs the expected outputs (as this JSON processing can be mirrored using non-vulnerable Python processses and the outputs can be compared).Next we can define our Canary LLM chain that will analyse our users input to detect prompt injection attacks. I’m using LangChain to simplify orchestration:
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
canary_prompt = PromptTemplate.from_template(canary_prompt)
model = OpenAI(temperature=0)
canary_chain = canary_prompt | model
We need to wrap this chain inside a function to generate the security keys and check the integrity of the output. Let’s use FastAPI so we can deploy this as part of a future application:
from fastapi import FastAPI
import secrets
import string
import json
app = FastAPI()
@app.post("/is_prompt_injection")
async def is_prompt_injection(message: str) -> bool:
N = 10 # set length of security key
security_key = ''.join(secrets.choice(string.ascii_letters + string.digits) for _ in range(N))
canary_json = canary_chain.invoke({"message": message, "security_key": security_key})
# check output compiles to JSON
try:
canary_json = json.loads(canary_json)
except json.JSONDecodeError as e:
return False
# compare the returned json vs. the expected json
if canary_json == {"message": message, "security_key": security_key}:
return True
else:
return False
We can extend this function as part of an overall pipeline by updating the /is_prompt_injection to become the primary endpoint (e.g.: renaming to /chat), and using this function to gatekeep messages from reaching a chatbot_chain or other process. For a complete example of this application, see my Canary framework on GitHub.
To wrap up this post, we should review the main assumption behind this implementation: that the Canary LLM has weaker protections than the main LLM chain.
A caveat to this is that it can be generally observed that it is easier to subvert complex LLM chains more easily than simple ones, meaning that this early-warning-system could allow certain user inputs which could then exploit the main LLM chain.
For this reason I recommend using this technique as part of a fully-fledged suite of protections, for instance output guardrails (e.g.: NeMO Guardrails by Nvidia), or moderation APIs (e.g.: OpenAI Moderation API [LangChain Docs]).
Get in touch: