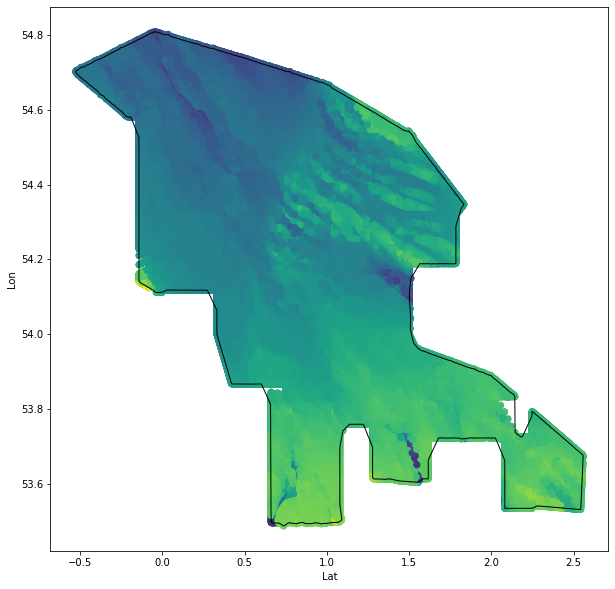
I want to talk about a unique problem of applying genetic optimisation to unusual search spaces. For my dissertation, I’m investigating a large section of seascape, off the East coast of England, to identify optimal sites for offshore wind farms (OWFs). I’ve been acquiring bathymetric data (depth of the sea at recorded points) as OWFs have a maximum depth for sinking pylons, apparently between 25-40m).
The search space is restricted in shape to complement the available depth data, resulting in this unusual shape:
 .
.
The irregular shape isn’t problematic itself - there is plenty of space within the boundary to optimise - but what is an issue is that is is difficult to restrict our optimiser to only finding solutions within the known search space.
A brief explanation of genetic optimisation is that is is an algorithmic method to searching a large search space efficiently, and find multiple viable solutions that balance conflicting objectives.
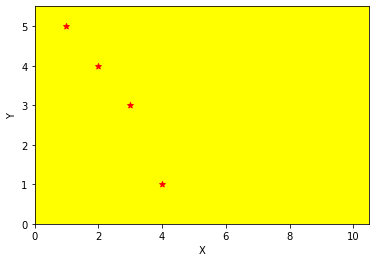
Let’s say we have an optimisation problem: you’re at the beach, and want to find a place to sit that isn’t too close to other people (this is our first objective: maximise the distance between us and other people), however, you also want to sit down quickly - so no walking for miles to the other end of the beach (this is our second objective: minimise the distance between where we enter the beach and then sit down).
Our beach is the search space - we can pick any point and say how good / bad it is, with a fitness (score) according to how well it minimises / maximises the objectives. So a solution will come in the form of some coordinates, precisely locating the best spot to sit.
Illustrating this beach, it might look like this (red dots are people we want to avoid):
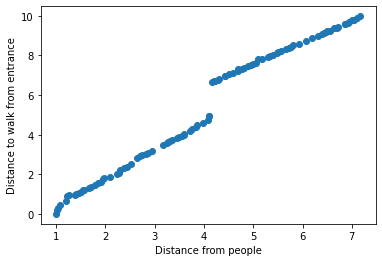
We can apply a popular genetic algorithm “Nondominated Sorting Genetic Algorithm II” (NSGAII) to this problem. The purpose of this algorithm is to search our search space and find solutions that are equally as good as each other. In other words, one solution might be 10% quicker to reach, but only 2M from another person, whilst another might be 10% slower to reach, but 2.2M from another person. These two solutions are equally as good, since we didn’t specify one objective as having precedence over another, so we consider them “mutually nondominating”. NSGAII will attempt to create a population of solutions that are all mutually nondominating, giving maximum choice to balance our objectives as we choose.
Plotting theses solutions according to their objective scores can identify the pareto front - a shape defining all nondominating solutions:
We can plot these solutions on our beach, to identify the best places to sit:
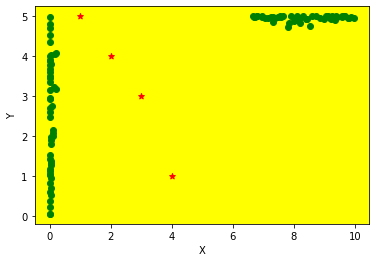
Each solution (in green) is a unique balance of distance from the entrance to the beach (at coordinates (0,5)) whilst avoiding sitting near other people (in red). The best solutions draw lines straight towards the entrance, as we want to minimise this objective, and shy away from the roughly diagonal spread of people (as we’re maximising our distance).
These principles can be applied to lots of different problem types.
Returning to our problem - imagine our search space was a triangle. A restriction of our genetic optimiser (at least using the Python package platypus-opt) is that we have to define our search space as a rectangle. Since our genetic optimisation is looking for X, Y coordinates, we can’t prevent solutions looking outside the dimensions of the triangle, since the optimiser thinks it has extra space to search.
However, if we can tell if our coordinates lie inside/outside the shape, we can encourage the optimiser to not stray outside the lines. If our beach was a triangle, or other weird polygon, then coordinates that aren’t valid could be given a fitness of ±infinity, strongly discouraging exploration of this space.
For our site selection, we need a more nuanced approach, as a solution may only slightly overlap the boundary, meaning we can instead optimise to maximise overlap of our site shape and the search space shape.
Our search space has an irregular shape:
Defining the shape of this collection of spatial data points is expensive, as we need to process 2.2 million data points, meaning the solution must be memory efficient.
I initially approached this problem considering methods to remove interior data points, reducing the dataset to only exterior points, however aforementioned memory issues prevented these quick-Google-methods. Discovery that this type of shape has a proper term in geometry - alpha-shape - was the key to finding a proper solution, as Stack Overflow was much more helpful now I knew what was needed.
Our final boundary was an approximation of the search space shape:
This boundary isn’t perfect, however it is more than accurate enough to allow us to properly determine overlap between our search space and solutions:
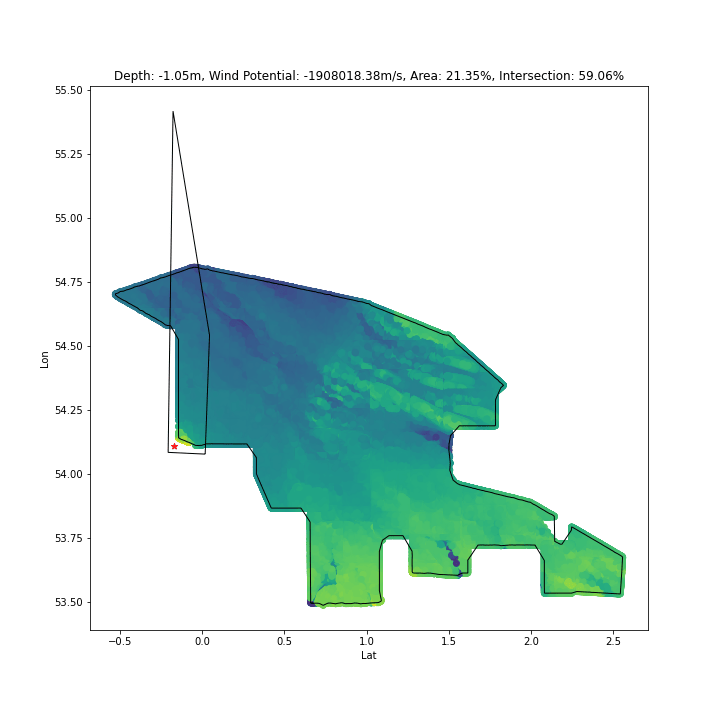
As above, by determing intersection % between our search space and solutions, we can encourage solutions to explore only inside the space:
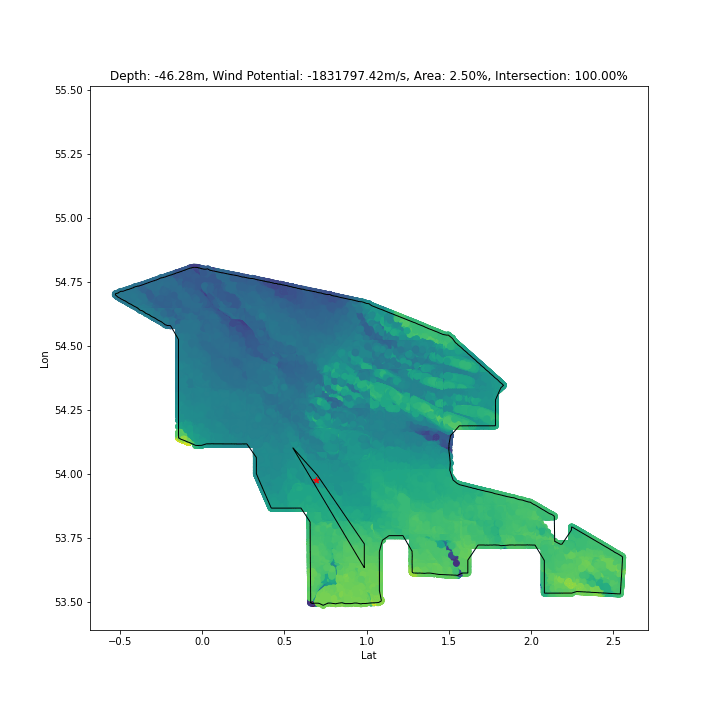
The biggest roadblock to progress in this stage was discovering the right mathematical geometry terms for what I was attempting - as ever, the problem was well established, but without the correct terminology searching didn’t get me anywhere fast.
My next goal is to fine tune the optimisation - possibly to force solutions to have ~99% intersection with the search space, as my current method results in some solutions with less intersection being judged “good enough”, which isn’t valid.
Get in touch: